How to run incremental and range run scripts in airflow
Here is a small post on a very specific use case of Airflow. While its not very difficult to do this, but I found really… Read More »How to run incremental and range run scripts in airflow

Here is a small post on a very specific use case of Airflow. While its not very difficult to do this, but I found really… Read More »How to run incremental and range run scripts in airflow
We had a EMR cluster reboot and hit this error all of sudden. The error is independent of EMR so worth sharing. Error: Caused by:… Read More »Spark-sql java.net.NoRouteToHostException on cluster reboot
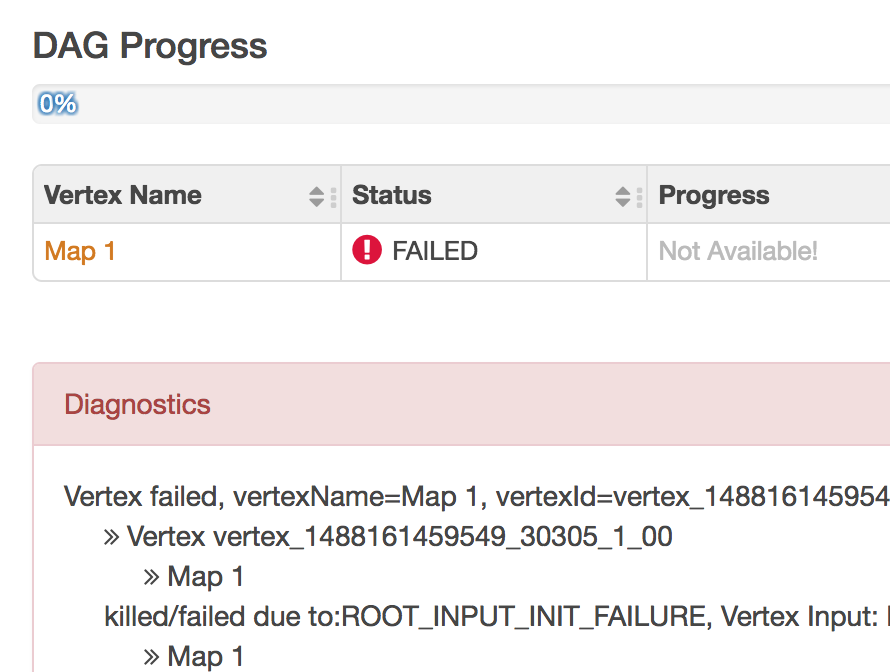
This was a fun debug activity for a Hive-on-S3 use case. Thought of writing a log of debug steps here before I lose the details.… Read More »Debugging : Hive DAG did not succeed due to VERTEX_FAILURE. Unable to rename output.

Papers We Love (PWL) is a community built around reading, discussing and learning more about academic computer science papers. This repository serves as a directory… Read More »Whitepapers and research materials on all things computer science

Introduction So this is a part 2 of a series of posts I am planning to write to create a very basic distributed system in… Read More »Create a basic distributed system in Go lang – Part 2- http server & JSON request/response
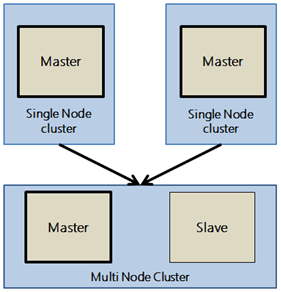
Introduction Yesterday I started looking into basics of Go – A relatively young programming language and though of learning it via creating some useful case… Read More »Create a basic distributed system in Go lang – Part 1
Just Look for the hive config file – On EMR emr-4.7.2 it is here – less /etc/hive/conf/hive-site.xml Look for the below properties in the hive-site <property> <name>javax.jdo.option.ConnectionURL</name>… Read More »How to connect/query Hive metastore on EMR cluster

Quick note – $ /usr/lib/hive/bin/schematool -dbType mysql -info Metastore connection URL: jdbc:mysql://ip-XX.XX.XX.XX:3306/hive?createDatabaseIfNotExist=true Metastore Connection Driver : org.mariadb.jdbc.Driver Metastore connection User: hive Hive distribution version: 0.14.0… Read More »How to get the Hive metastore version on EMR cluster

[Fatal Error] total number of created files now is 900320, which exceeds 900000. Killing the job. tldr; quick fix – but probably not the right thing… Read More »Debugging : Hive Dynamic partition Error : [Fatal Error] total number of created files now is 100028, which exceeds 100000. Killing the job.
Code- dataDF.write.partitionBy(“year”, “month”, “date”).mode(SaveMode.Append).text(“s3://data/test2/events/”) Error- 16/07/06 02:15:05 ERROR datasources.DynamicPartitionWriterContainer: Aborting task. java.io.IOException: File already exists:s3://path/1839dd1ed38a.gz at com.amazon.ws.emr.hadoop.fs.s3n.S3NativeFileSystem.create(S3NativeFileSystem.java:614) at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:913) at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:894) at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:791) at com.amazon.ws.emr.hadoop.fs.EmrFileSystem.create(EmrFileSystem.java:177)… Read More »Spark append mode for partitioned text file fails with SaveMode.Append – IOException File already Exists
A compressed format can be specified in spark as : conf = SparkConf() conf.set(“spark.hadoop.mapred.output.compress”, “true”) conf.set(“spark.hadoop.mapred.output.compression.codec”, “true”) conf.set(“spark.hadoop.mapred.output.compression.codec”, “org.apache.hadoop.io.compress.GzipCodec”) conf.set(“spark.hadoop.mapred.output.compression.type”, “BLOCK”) The same can be… Read More »How to write gzip compressed Json in spark data frame
I have been facing trouble with a basic spark sql job which was unable to process 10’s of gigs in hours. Thats when I demystified… Read More »Spark Sql job executing very slow – Performance tuning