

Hey readers, in previous post I have explained How to create a python ETL Project. In this post, I will explain how we can schedule/productionize our big data ETL through Apache Airflow.
Apache Airflow
Airflow is an open source scheduler that helps to schedule job, executing and monitoring the workflow of job. The primary use of Apache airflow is managing workflow of a system. For more about Apache Airflow you can see the documentation here.
Importance of Apache Airflow
The main reasons which signify the Importance of Apache Airflow are :
- It provides the power of scheduling the analytics workflow.
- The logs entries of execution concentrated at one location.
- It has a strength to automate the development of workflows as it configures the workflow as a code.
Basic concepts of Apache Airflow
Some basic concepts of Airflow we should know about before installing Airflow and scheduling our ETL job with Airflow :-
DAGs
DAGs (Directed Acyclic Graphs) is a collection of all the tasks we want to run, organised in a way that reflects their relationships and dependencies.
Operator
An operator describes a single task in a workflow. Operators determine what actually executes when your DAG runs. Airflow provides operators for many common tasks, including : –
BashOperator– executes a bash commandPythonOperator– calls an arbitrary Python functionEmailOperator– sends an emailSimpleHttpOperator– sends an HTTP requestMySqlOperator,SqliteOperator,PostgresOperator,MsSqlOperator,OracleOperator,JdbcOperator, etc. – executes a SQL commandSensor– waits for a certain time, file, database row, S3 key, etc…In addition to these basic building blocks, there are many more specific operators:DockerOperator,HiveOperator,S3FileTransformOperator,PrestoToMysqlOperator,SlackOperator
Task
Once an operator is instantiated, it is referred to as a “task”. The instantiation defines specific values when calling the abstract operator, and the parameterised task becomes a node in a DAG.
Task Instance
A task instance represents a specific run of a task and is characterized as the combination of a dag, a task, and a point in time. Task instances also have an indicative state, which could be “running”, “success”, “failed”, “skipped”, “up for retry”, etc.
Installation
Before installing Airflow create airflow folder in your home directory which is optional.
$ mkdir ~/airflow $ export AIRFLOW_HOME=~/airflow $ sudo -H SLUGIFY_USES_TEXT_UNIDECODE=yes pip install apache-airflow==1.10.0
Note :-One of the dependencies of Apache Airflow by default pulls in a GPL library (‘uni decode’). In case this is a concern we can force a non GPL library by issuingexport SLUGIFY_USES_TEXT_UNIDECODE=yes and then proceed with the normal installation.
Airflow stores it’s metadata in sqlite. Use this command to initialise airflow database.
$ airflow initdb
Now, we can start Airflow by using following command :-
$ airflow webserver -p 8080

Note : Also notice the highlighted box above. It shows the directory where Airflow expects the new DAGs.
Now, open browser and go to localhost:8080 to view and use UI
url : http://localhost:8080

Airflow provides you bunch of sample DAGs to play around with and to get comfortable with Airflow.
Code to schedule job with Airflow
The best way to explain the concepts is through the code. Previously I have explained how to create ETL job. Here I will explain how we can schedule that ETL job through Airflow. All the code discussed below can be found on my Github repo here.
Creating airflow DAGs
A DAG basically describes how we want to carry out our workflow. DAGs job is to make sure that whatever they do happens at the right time, or in the right order, or with the right handling of any unexpected issues.
So, here we will see how we can convert our Python ETL jobs to Airflow Dag.
Let’s have a look how our ETL job previously looks like and how it looks after scheduling through Airflow.
On the left side we have a generate data ETL and on the right side we create our Airflow DAG for the same job.

In above, we can see that to create a Dag we need to pass the function to perform, schedule_interval which take a particular time to run the script and default_args which contain owner of the Dag and start date of the DAG.
All the python function now gets called by the PythonOperator and we connect all the individual task/operator into a DAG in the end.
Creating an Airflow custom operator
Creating a custom operator is a best practices as it makes our code more readable and we can reuse it for other Airflow problems. Here I have created a Hive custom operator.
We can see on the left side there is a utility function of our ETL and on the right side I have converted that utility function to a custom operator.
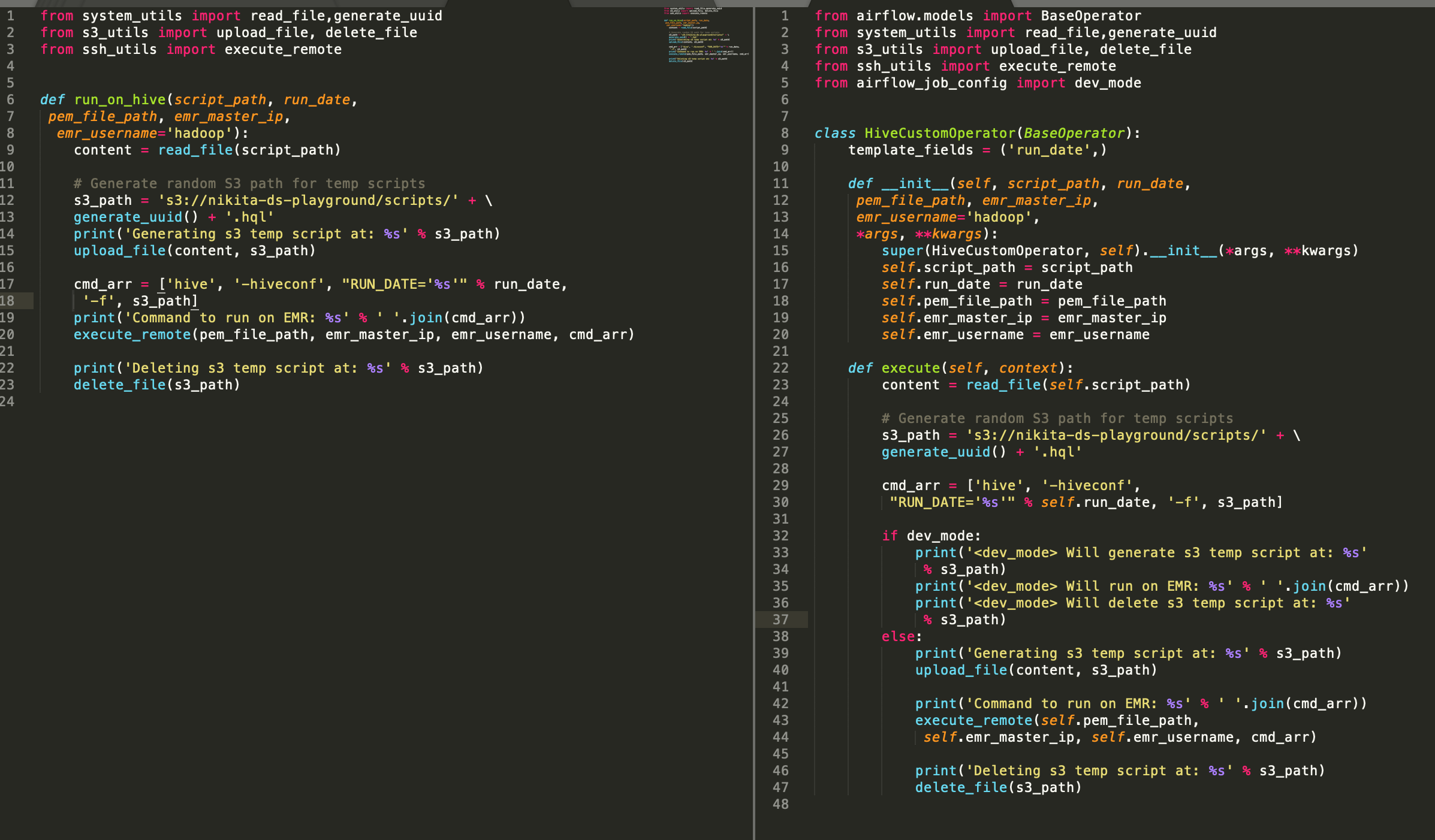
Note :- you might notice I am using a flag called dev_mode to skip remote/emr commands and perform a dry run. We are specifying the dev_mode in our configuration file.
Now we need to register our operator with Airflow. We are creating a file called airflow_plugins.py to register our operator.

Using custom operator in DAGs
Creating a task requires providing a unique task_id and DAG container in which to add the task. Pass all the expected parameters to our custom operator.

That’s it and we have our DAG with custom operator ready.
Deploying the DAGs to Airflow
Now it’s time to deploy our DAGs file to Airflow.
Below command will automatically copy our folder to the given path where we can exclude the file which we don’t want to copy. We need to run this command every time we add a new DAG or make changes to common python modules.
cd ~/Airflow rsync -arv --exclude=venv --exclude=.git --exclude=.idea ~/work/code/airflow-jobs/ ~/Airflow/code/
After copying the folder to the path we have to export the PYTHONPATH. The business of telling Python where to look for modules is handled by setting the PYTHONPATH environment variable, which lists the directories Python should look in (besides the default ones) when a script imports a module.
export PYTHONPATH=~/Airflow/code/:$PYTHONPATH
We have to specify the plugin directories and dag folder in airflow.cfg which can be found at ~/Airflow/airflow.cfg
vim ~/Airflow/airflow.cfg
Add following command in it.
plugins_folder = ~/Airflow/code/common dags_folder = ~/Airflow/code/dags
Now we are ready to schedule our job by following command. Start them in different terminals or in the background.
airflow scheduler airflow webserver -p 8080


Hope this post will be helpful for you. Stay tuned for more blogs.