

Hey Readers, this is my first blog on Deep Learning. From last few months I have started learning about Deep learning. Thanks to guru99 where I learned a lot about neural network. To start my journey in deep learning I choose a simple dataset to learn the concept of neural network.I have used the MNIST dataset, which contains images of handwritten digits for my first example of neural networks.
This post explains CNN in brief and explains how to construct a CNN and how to use TensorFlow for a beginner. All the code discussed below can be found on my Github repo here.
Convolutional Neural Network (CNN)
CNN is a class of deep neural networks used to recognise objects from a picture or video. A CNN is not very difficult to understand.
- An image is pushed to the network called input image.
- The input image goes through a multiple number of steps called convolutional part of the network.
- Finally the neural network can predict the digit/object on the image.
We will discuss each part in detail below.
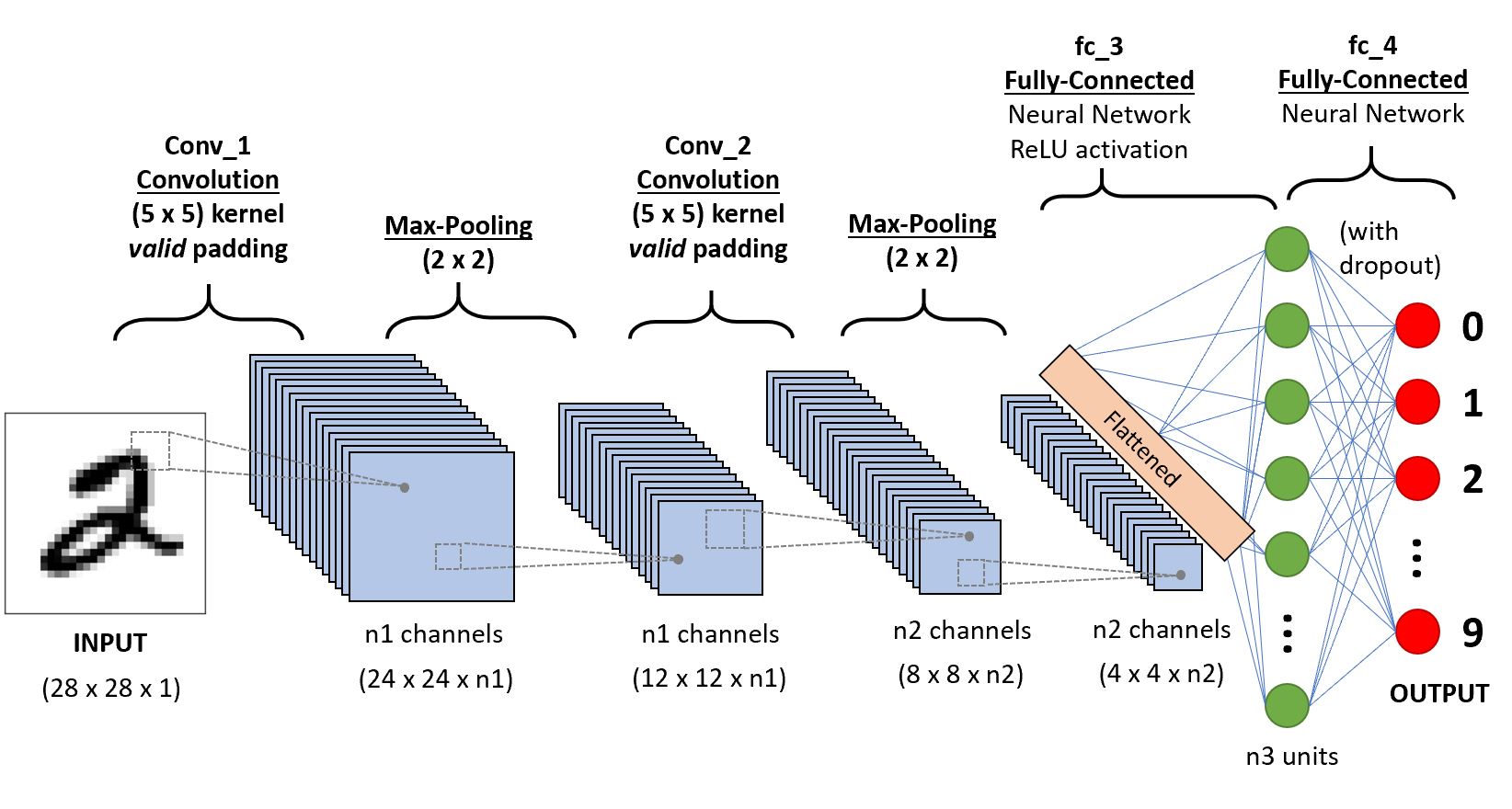
Components of CNN
To explain CNN, there are 4 basic components :
- Convolutional Layer
- Non-Linearity (RELU)
- Pooling or subsampling
- Fully connected layers
Convolutional Layer
The most critical component in the model is the convolutional layer. The purpose of convolutional is to extract the features of the object on the image and reduces the size of the image for faster computations.. Here, the network will learn specific patterns within the picture and will be able to recognise it everywhere in the picture.
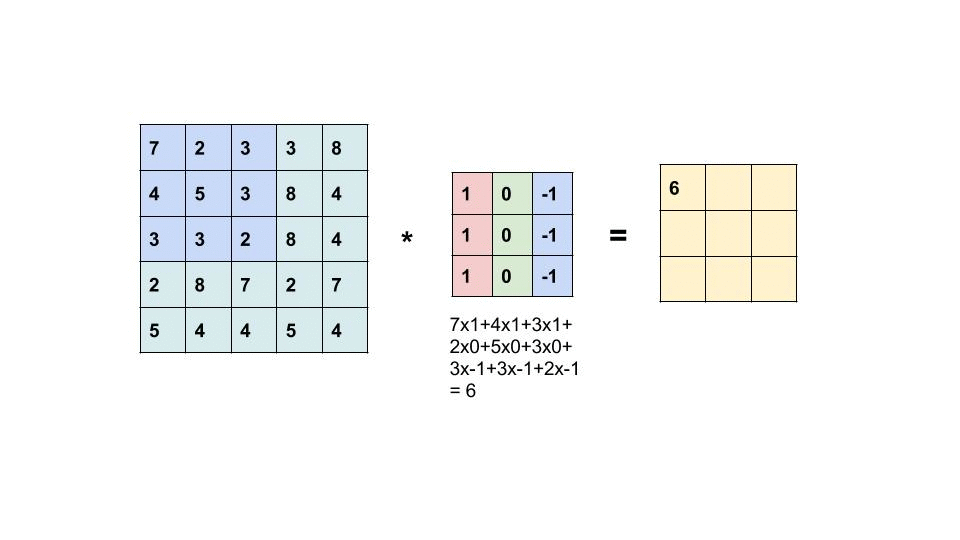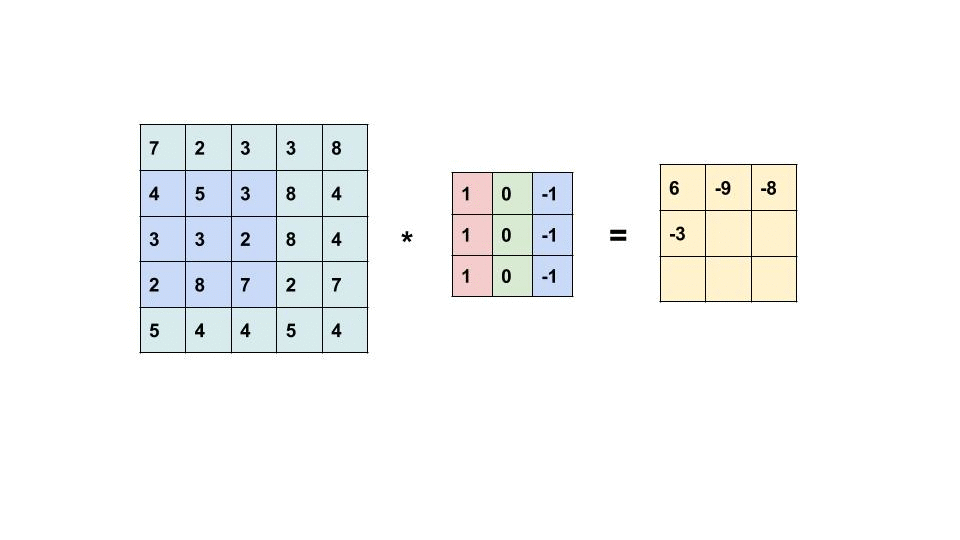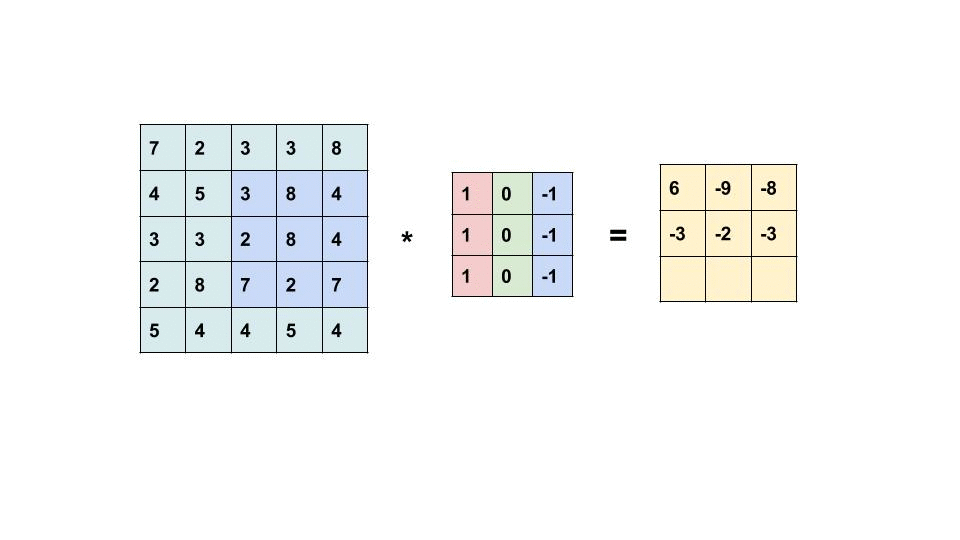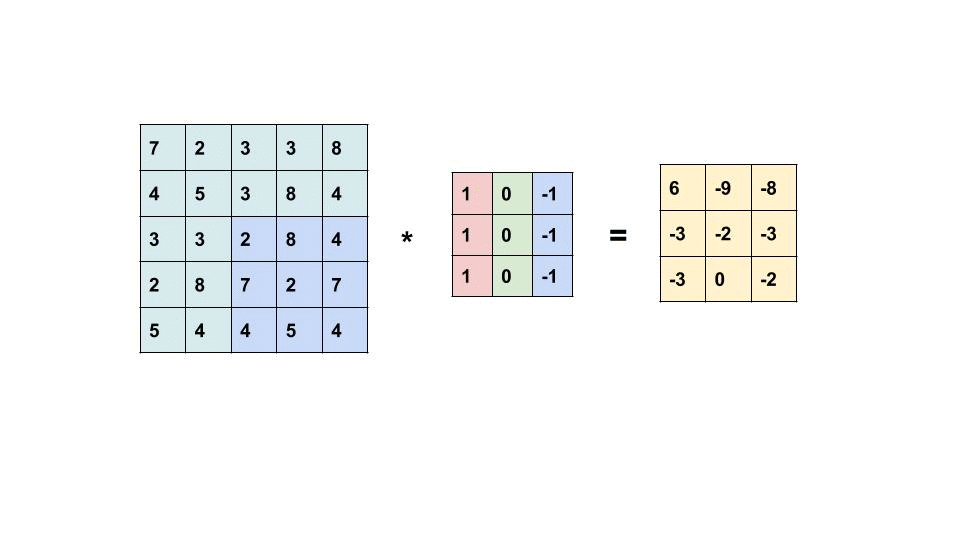
As we can see the above image shows how the convolution operates. The computer scan a part of the image with a dimension of 5×5 image input and multiplies with a 3×3 filter to produce a 3×3 feature map as output. Note that, after the convolution, the size of the image is reduced.
Non-Linearity (RELU)
After Convolution, the output is subject to an activation function to allow non-linearity. Almost all deep learning Models use ReLu nowadays. But its limitation is that it should only be used within Hidden layers of a Neural Network Model. In this, all the pixel with a negative value will be replaced by zero.

Pooling or subsampling
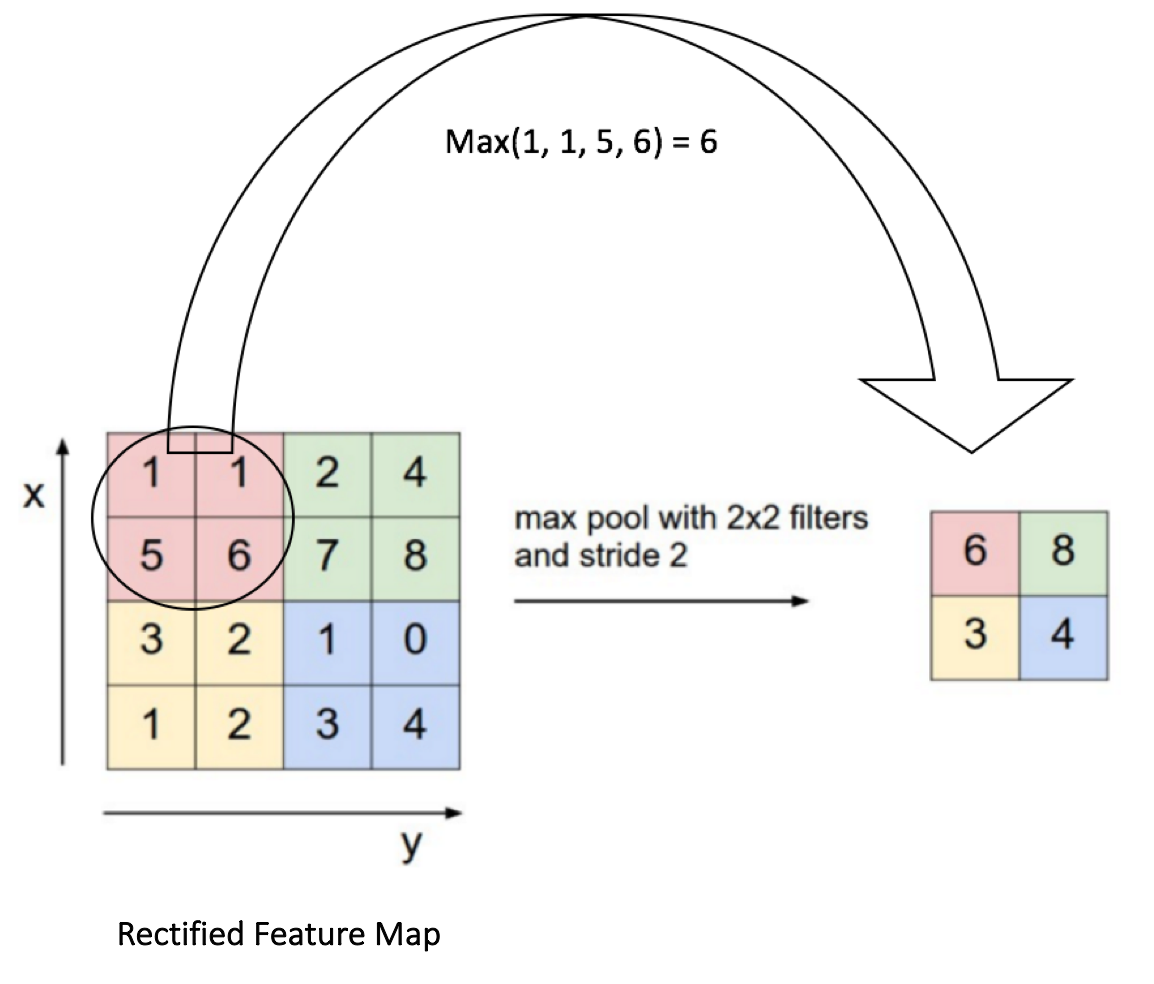
The main purpose of the pooling is to reduce the dimensionality of the input image. By diminishing the dimensionality, the network has lower weight to compute, so it prevents overfitting.
From the image, we can see that pooling takes the maximum value of a 2×2 array and then move this windows by two pixels. For instance, the first sub-matrix is [1,1,5,6], the pooling will return the maximum, which is 6.
Fully Connected layer
Here, we connect all neurons from the previous layer to the next layer. We use a softmax activation function to classify the number on the input image.

After getting the concepts of CNN, we are ready to build one with TensorFlow. We will use the MNIST dataset for image classification.
Building the CNN with TensorFlow
Here we are taking MNIST dataset from Kaggle. MNIST (“Modified National Institute of Standards and Technology”) is the de facto “hello world” dataset of computer vision. Our goal is to correctly identify digits from a dataset of tens of thousands of handwritten images.
Step 1: Upload Datasets
First, we will download the dataset from Kaggle to run the code on our local system or write code directly on Kaggle kernel. Then we will import library and load the dataset.
we need to split the dataset with train_test_split
After split train and test , we can scale the feature with MinMax Scaler.
Step 2 : Input layer
We need to define a tensor with the shape of the data. For that we can use the module tf.reshape . We need to declare the tensor to reshape and the shape of the tensor.
Step 3 : Convolutional layer
The first convolutional layer has 14 filters with a kernel size of 5×5 with the same padding. The same padding means both the output tensor and input tensor should have the same height and width.
Step 4 : Pooling layer
We know pooling layer will help to reduce the dimensionality of the data. Here, we can use max_pooling2d with a size of 2×2 and stride of 2.
Step 5 : Second Convolutional layer and pooling layer
Step 6 : Dense layer
Here, we need to define the fully connected layer. The feature map has to be flatten before to be connected with the dense layer. We add a dropout regularization term with a rate of 0.3, meaning 30 percents of the weights will be set to 0.
Note that, the dropout takes place only during the training phase.
Step 7 : Logit layer
Finally we can define the last layer with the prediction of the model. And we can create a dictionary containing the classes and the probability of each class.
The module tf.argmax() with returns the highest value if the logit layers. The softmax function returns the probability of each class.
And then compute the loss of the model (for both train and eval mode)
The final step is to optimize the model. The objective is to minimize the loss. We also want to display the performance metrics during the evaluation mode.
Step 8 : Define an Estimator
We define an estimator with the CNN model. A CNN takes many times to train, therefore, we create a Logging hook to store the values of the softmax layers every 50 iterations.
Step 9 : Train the model
We are ready to estimate the model. We set a batch size of 100 and shuffle the data. Note that we set training steps of 20.000, it can take lots of time to train. Be patient.
Step 10 : Evaluate the Model
After training the model, now we can evaluate it.
We get an accuracy of 96%. We can change the number of iteration to improve the accuracy.
After increasing the no. of iteration to 70k , I achieved 98.5 % accuracy in Kaggle. You can go through here.
Step 11 : Predict the Model
Finally we can predict our model with test data and submit to Kaggle competition.
That’s all for this post. Hope this will helpful for you. Stay tune for more blogs on Deep Learning.