Notes on Fenwick tree
The Fenwick tree is more popularly known as the Binary Indexed Tree which works solves the Range Sum Queries problems. The same can be achieved… Read More »Notes on Fenwick tree

The Fenwick tree is more popularly known as the Binary Indexed Tree which works solves the Range Sum Queries problems. The same can be achieved… Read More »Notes on Fenwick tree
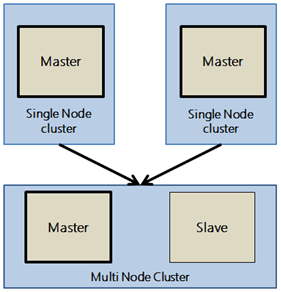
Introduction Yesterday I started looking into basics of Go – A relatively young programming language and though of learning it via creating some useful case… Read More »Create a basic distributed system in Go lang – Part 1

This post have been on hold for a really long time. I have finally moved out of India after long 26 years on this adventurous… Read More »Yash joins Atlassian

Export Go path export GOPATH=/Users/ysharma/work/go/ Directory Structure . ├── bin │ ├── main │ └── test ├── pkg │ └── darwin_amd64 │ └── rect.a └──… Read More »Hello Go – Scratching the surface
Just Look for the hive config file – On EMR emr-4.7.2 it is here – less /etc/hive/conf/hive-site.xml Look for the below properties in the hive-site <property> <name>javax.jdo.option.ConnectionURL</name>… Read More »How to connect/query Hive metastore on EMR cluster

Quick note – $ /usr/lib/hive/bin/schematool -dbType mysql -info Metastore connection URL: jdbc:mysql://ip-XX.XX.XX.XX:3306/hive?createDatabaseIfNotExist=true Metastore Connection Driver : org.mariadb.jdbc.Driver Metastore connection User: hive Hive distribution version: 0.14.0… Read More »How to get the Hive metastore version on EMR cluster

[Fatal Error] total number of created files now is 900320, which exceeds 900000. Killing the job. tldr; quick fix – but probably not the right thing… Read More »Debugging : Hive Dynamic partition Error : [Fatal Error] total number of created files now is 100028, which exceeds 100000. Killing the job.
Code- dataDF.write.partitionBy(“year”, “month”, “date”).mode(SaveMode.Append).text(“s3://data/test2/events/”) Error- 16/07/06 02:15:05 ERROR datasources.DynamicPartitionWriterContainer: Aborting task. java.io.IOException: File already exists:s3://path/1839dd1ed38a.gz at com.amazon.ws.emr.hadoop.fs.s3n.S3NativeFileSystem.create(S3NativeFileSystem.java:614) at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:913) at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:894) at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:791) at com.amazon.ws.emr.hadoop.fs.EmrFileSystem.create(EmrFileSystem.java:177)… Read More »Spark append mode for partitioned text file fails with SaveMode.Append – IOException File already Exists
A compressed format can be specified in spark as : conf = SparkConf() conf.set(“spark.hadoop.mapred.output.compress”, “true”) conf.set(“spark.hadoop.mapred.output.compression.codec”, “true”) conf.set(“spark.hadoop.mapred.output.compression.codec”, “org.apache.hadoop.io.compress.GzipCodec”) conf.set(“spark.hadoop.mapred.output.compression.type”, “BLOCK”) The same can be… Read More »How to write gzip compressed Json in spark data frame
I have been facing trouble with a basic spark sql job which was unable to process 10’s of gigs in hours. Thats when I demystified… Read More »Spark Sql job executing very slow – Performance tuning
Here is a crisp post to index Data in Solr using Python. 1. Install Pre-requisites – pip – PySolr 2. Python Script #!/usr/bin/python import sys,… Read More »Indexing csv data in Solr via Python – PySolr
TLDR; A Pig Logical plan is the Plan DAG that is used to execute the chain oj Jobs on Hadoop. Here is the code snippet… Read More »How to get Pig Logical plan (Execution DAG) from Pig Latin script