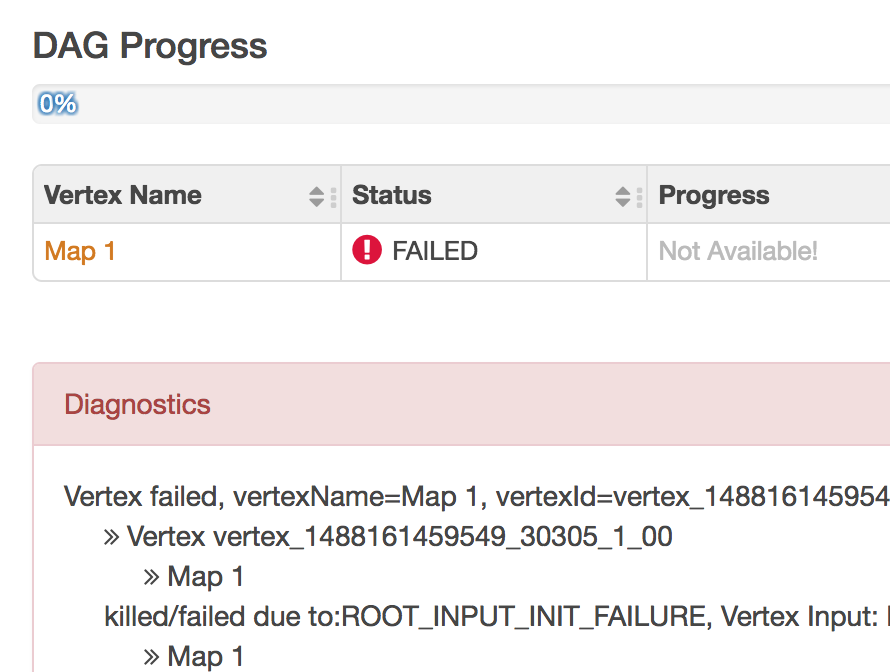
Real world application project for Big Data – with Apache Spark and AWS-EMR

Hey readers, I am learning Data Engineering from last few months and I thought of sharing my learning with you all. Recently I made a project… Read More »Real world application project for Big Data – with Apache Spark and AWS-EMR